Three problems of converted files


1. Broken Sentences
CAT tools save us a great deal of time and effort by automatically handling text repetitions and performing quality assurance tasks. However, none of these would matter if your source document was not properly segmented before translating with your CAT tool.
Why? Let’s see…
At the preparatory stage, before translation, a CAT tool runs a task called segmentation, which splits the document’s text into manageable segments.
A segment is a text unit (typically, a sentence) to be processed. The end of each segment is determined by appropriate punctuation: a period (full stop), exclamation or question mark, or ellipsis. In case of tables, drawings, or diagrams, segments are delimited by a paragraph mark, page break, end-of-row marker in table cells, etc.
In 90% of cases, automatic conversion results in the appearance of extraneous paragraph marks and sentence breaks, usually at the end of a line or page.
In MS Word, it may look like this:

This is how your CAT may then segment such text:
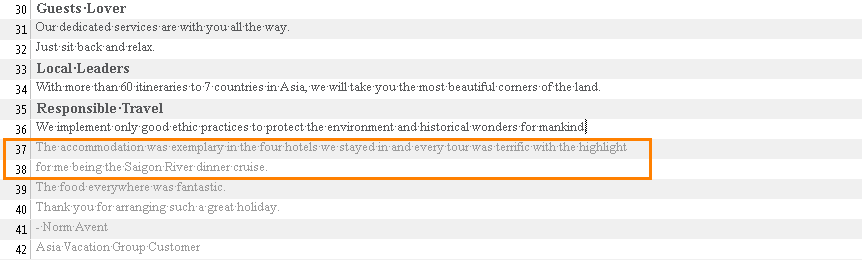
Translating a broken sentence can require several extra steps: for example, blocking segment #38 and entering the translation of the whole sentence in the corresponding target field. If each page had at least several such breaks, imagine how long it would take to translate 100 or 200 pages like that!
And that’s not all. In your TM, only part of the source text will be stored, but the full target translation will be added, which means you won’t be able to retrieve it properly when translating other documents in the future.
With our 1-to-1 PDF to DOC conversion service, OCR Craft is happy to make any of your projects that need automatic PDF conversion easier. If you need to translate a PDF file, feel free to send it to us. We will respond within 20 minutes with an estimated quote, including the price and turnaround time for your project.
2. Text Segmentation
Have you ever wondered how missegmentation might have affected the quality of your deliveries? Like, when you add a letter in a word only to see the entire formatting of the file fall apart right in front of your eyes?
Breaks in the document structure usually result from automatic PDF to Word conversions.
When working with non-Asian languages, CATs are programmed to read text line by line from left to right. However, if the structure is disrupted and the text becomes missegmented, translating the file will be more difficult.
One of the source file elements that frequently causes missegmentation is a table with hidden gridlines. In fact, most autoconversion problems are due to this source element.
Below is a typical table with gridlines set “hidden”:

And here is the same table, only post-autoconversion:
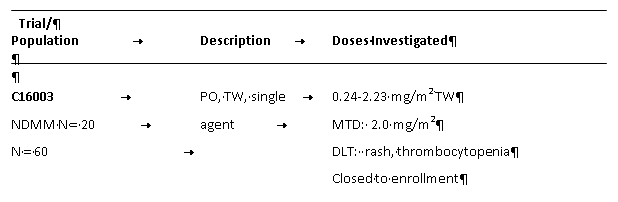
This is how the table text appears in a standalone CAT environment:

The highlighted segments above should actually be in the same sentence. As you can see, the sentences are clearly broken.
At OCR Craft, we are glad to save you time and effort by resolving any missegmentation issues that may occur during the 1-to-1 PDF to DOC conversion.
3. Formatting Tags
Have you considered how irrelevant tags might have delayed your translation projects and impacted the quality of your final deliverables?
CATs usually format their tags as colored flags, and any such tag in the source segments must be mirrored in their corresponding target segments. While many tags are relevant (such as hyperlinks, footnotes, images, etc.), some are indeed irrelevant.
Any autoconverted PDFs almost always end up having some tags that are irrelevant! Their number might be so large that formatting tags could take as long as translating the text itself.
Below are the screenshots of the same text with relevant tags (right) and irrelevant tags (left) to compare:
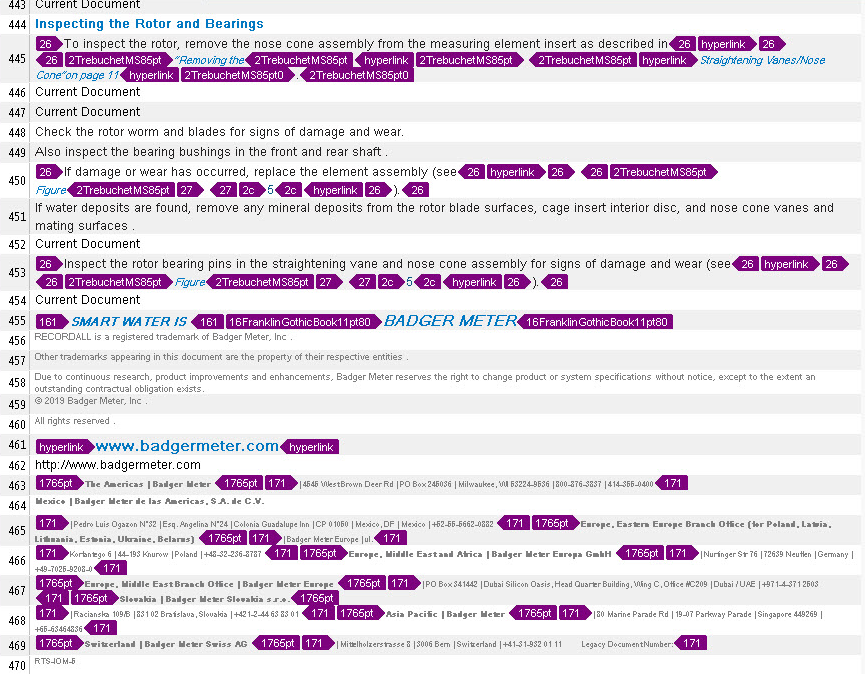
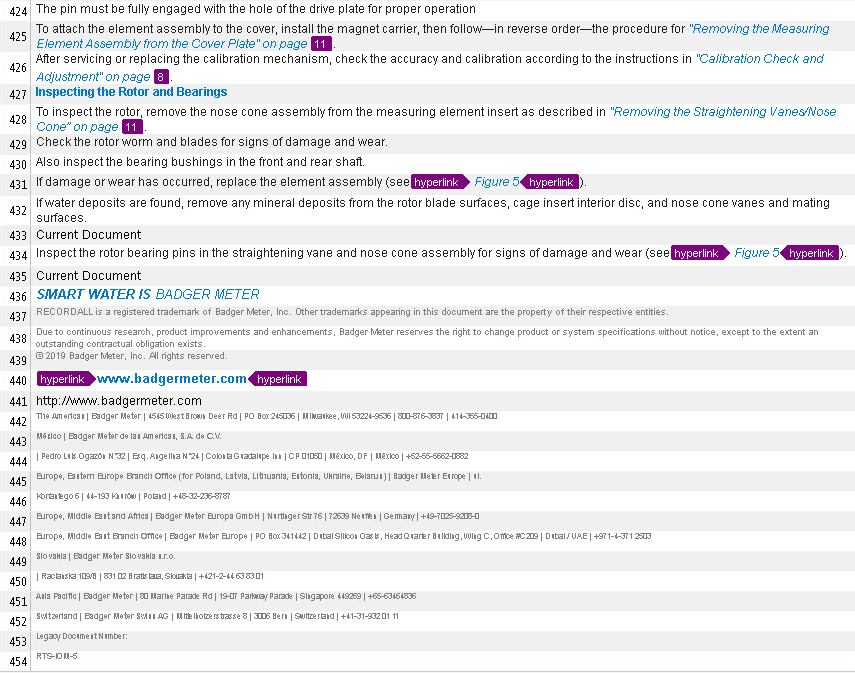
The difference, to say the least, is substantial!
Would you still use autoconversion in your translation projects?
At OCR Craft, we are happy to assist with projects involving 1-to-1 PDF to DOC conversions and DTP skills, including InDesign, AutoCAD, Photoshop, Illustrator, and Articulate Storyline.